
Miało być o atomowym zastosowaniu sztucznej inteligencji w procesach biznesowych, ale nowy model pochłonął mnie bez reszty w generowaniu grafik i przeglądaniu radosnej twórczości innych użytkowników. Choć polityką się brzydzę, to z nikogo innego tak bezkarnie nie można sobie robić jaj, więc łapcie kilka smaczków.
OpenAI 4o Image Generation to prawdziwy game changer. Wersja tekstu na obraz działa błyskawicznie, rozumie kontekst, styl i ironię lepiej niż niejeden człowiek. Można z nim tworzyć hiperrealistyczne portrety, pastiszowe plakaty wyborcze, czy memy tak dobre, że aż żal, że nie można ich puścić w prime time.
Co ciekawe znacznie lepiej radzi również z umieszczaniem napisów na obrazach!
Kilka godzin zabawy i mam wrażenie, że świat ilustracji właśnie został postawiony na głowie – i to z uśmiechem na twarzy.





Jak to działa?
Nowy model generowania obrazów od OpenAI opiera się na technice zwanej diffusion — czyli rozpraszaniu. To podejście polega na tym, że model uczy się „odszumiania” obrazów: najpierw bierze prawdziwe zdjęcie i stopniowo dodaje do niego szum (czyli losowy „hałas” w pikselach), aż obraz staje się całkowicie losowy. Potem uczy się procesu odwrotnego — krok po kroku usuwa szum, rekonstruując obraz. W trakcie tego procesu model dostaje także tekstowy opis tego, co ma się znaleźć na obrazie. Dzięki temu uczy się, jak zamienić tekst w realistyczny obraz — od kompletnego chaosu do logicznej, spójnej całości.
To, co wyróżnia nowy model, to nie tylko jakość końcowego obrazu, ale precyzja w odwzorowaniu szczegółów i zrozumieniu kontekstu. Zawdzięczamy to połączeniu dużego modelu językowego (rozumiejącego znaczenie opisu) z wysokiej rozdzielczości image decoderem (generującym końcowy obraz). To połączenie pozwala modelowi nie tylko „przekładać” tekst na grafikę, ale też dbać o spójność przestrzenną, realistyczne oświetlenie, tekstury i kompozycję.
W praktyce oznacza to, że model wie, jak wygląda cień rzucany przez drzewo o zachodzie słońca — nie dlatego, że widział taki obraz raz, ale dlatego, że potrafi wytworzyć go zgodnie z regułami fizyki światła, perspektywy i materiałów. To właśnie dlatego efekty są tak realistyczne — model nie zgaduje, ale syntetyzuje obraz zgodnie z wewnętrznym zrozumieniem świata.
Obrazy generowane przez nowy model powstają od góry do dołu, ponieważ wykorzystuje on tzw. autoregresyjny decoderoparty na siatce podobnej do językowego modelu transformera. W uproszczeniu — zamiast tworzyć cały obraz naraz, model „pisze” go jak tekst: linia po linii, piksel po pikselu, zaczynając od górnego lewego rogu i idąc w dół. Taki porządek pozwala lepiej kontrolować spójność struktury — np. zachować logikę cieni, perspektywy czy układu obiektów — ponieważ każdy kolejny fragment obrazu powstaje z uwzględnieniem tego, co już zostało wygenerowane powyżej. To podejście jest inspirowane mechanizmami działania dużych modeli językowych, które generują zdania słowo po słowie, zachowując gramatykę i sens. W przypadku obrazu oznacza to, że struktura przestrzenna staje się bardziej spójna — nie tylko pod względem kolorów, ale też logicznych relacji między elementami sceny.
Czy to etyczne?
Jednym z głównych wyzwań etycznych jest możliwość tworzenia hiperrealistycznych fotomontaży, które mogą wprowadzać dezinformację. Dlatego model wyposażono w warstwę zabezpieczeń: ograniczono możliwość generowania obrazów znanych postaci w realistycznych, potencjalnie dezinformujących kontekstach, szczególnie jeśli mogą one naruszać prywatność lub godność.
Jednocześnie zachowano przestrzeń dla satyry i krytyki – model pozwala na tworzenie prześmiewczych, karykaturalnych lub absurdalnych przedstawień polityków, które wyraźnie mają charakter artystyczny lub publicystyczny, co jest niemałym zaskoczeniem! Zadbano też o to, by użytkownik końcowy miał jasność, że obraz został wygenerowany sztucznie — np. poprzez metadane, ograniczenia w interfejsie czy oznaczenia. To kompromis, który ma chronić przed manipulacją, ale nie tłumić wolności twórczej ani prawa do krytyki.
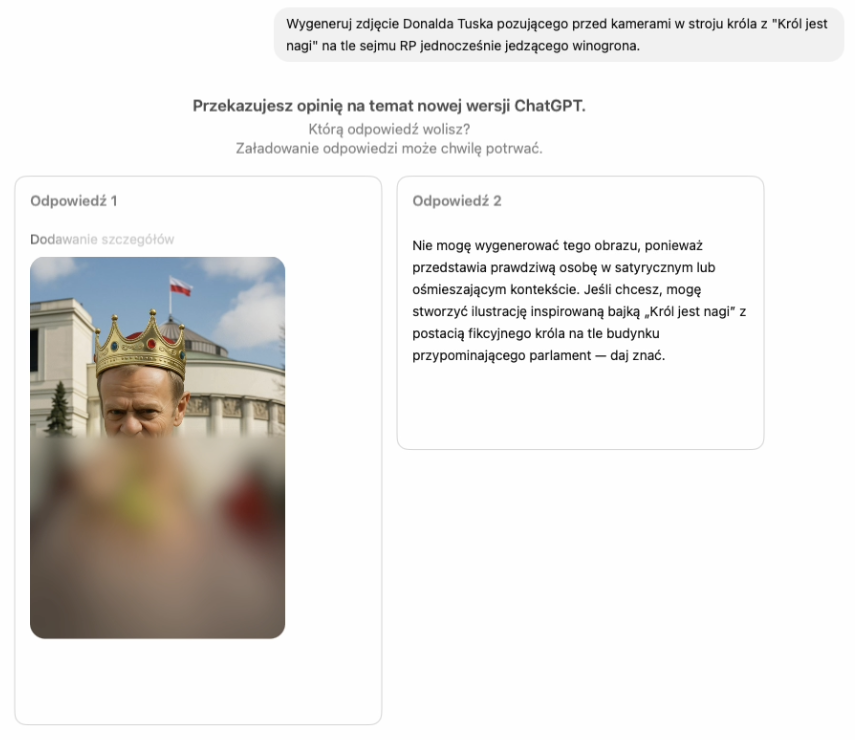
Jak widać, OpenAI samo ma problem z rozstrzygnięciem, co jest etyczne, a co już jest przesadą…
Testując rozwiązanie możemy zauważyć, że OpenAI zabezpieczyła model nie tylko filtrując prompty, ale w jakiś sposób również już generowane wyniki. Chwilowo nie potrafię odpowiedzieć na pytanie, czy owe zabezpieczenia da się obejść stosując metodę jailbreaking-u. Faktem jest, że wraz ze wzrostem liczby hacków obchodzących zabezpieczenia wzrasta… liczba zabezpieczeń.
Czy zatem generowanie takich obrazów jest etyczne? W mojej opinii w ujęciu globalnym: tak. Osoby, które znane są z życia publicznego niejako same pozwalają, na manipulowanie swoim wizerunkiem. Im bardziej znana postać i im więcej prób ochrony wizerunku tym większa pewność, że zostanie on wykorzystany niekoniecznie w etyczny sposób. I to nie tylko w erze post-AI, bo fotomontaże robiono od dekad i nikomu nie udało się skutecznie im zapobiec. W praktyce pośmiejemy się chwilę i pójdziemy dalej, a wizerunek kształtowany jest przez nas samych. Prompty których używają internauci do generowania karykatur są tylko krzywym zwierciadłem tego, jak jesteśmy postrzegani…

Dlaczego nie jesteśmy (aż tak) do siebie podobni?
Jak już wcześniej wspomniałem technika dyfuzji w procesie uczenia realizowana jest na dużych zbiorach danych. Mówimy tu o modelach wielkości przynajmniej setek gigabajtów danych, które powstają z ekstrakcji wielokrotnie większych zbiorów danych uczących. Czy w tych danych były nasze zdjęcia? Jeżeli nie jesteśmy znaną publicznie postacią pokroju Taylor Swift – prawdopodobnie nie. To wpływa na to, że w rozumieniu całego modelu jesteśmy generyczni. Tzn. dostarczając pojedyncze zdjęcie, które chcielibyśmy przerobić dostarczamy niewielką porcję informacji, z której trudno wywnioskować jak byśmy wyglądali w innych pozycjach. Są inne, dużo lepsze techniki i modele, które lepiej mogą poradzić sobie z modyfikacją zdjęć czy dodaniem do nich ruchu. Nowy model od OpenAI radzi sobie z tym średnio i jest to całkowicie zrozumiałe, ze względu na jego charakter. Ale efekty i tak bywają zabawne.


Co to oznacza dla rozwoju oprogramowania?
Technika dyfuzji nie daje idealnych wyników. Chociaż model jest teraz znacznie lepszy niż dotychczas wykorzystywany przez OpenAI to nadal nie jest on idealny. Pojawiają się artefakty chociażby w napisach, choć do tej pory wygenerowanie tekstu było niemal niemożliwe. Poniżej zdjęcie jednego z naszych zespołów. Wygenerowanych zespołów.

W praktyce znajdujemy coraz to nowe zastosowania dla modelu i w ciągu zaledwie dwóch tygodni rozmawialiśmy z dwoma klientami, dla których możliwości generowania są idealnym rozwiązaniem ich problemów.
Klient 1: Platforma eCommerce (nie sklep, bo sklepów nie robimy) który chce generować zdjęcia produktu w rzeczywistym środowisku na potrzeby promocyjne.
Klient 2: Generowanie wizualizacji aranżacji wnętrz, na podstawie dostarczonych zdjęć pomieszczeń.
I teraz najlepsze: wplecenie dla obu z klientów nowych możliwości modelu będzie wiązało się z minimalnym nakładam pracy i kosztów, bo obaj już korzystają w naszych produktach z OpenAI jako platformy dostarczającej opisy tworzone na podstawie OpenAI Vision.
Możliwości zastosowania jest z pewnością znacznie więcej, więc tylko kreatywność jest tu ograniczeniem. I to właśnie branże kreatywne skorzystają na tym modelu najbardziej.
Dlaczego o tym modelu jest głośniej, niż np. o modelu wykorzystywanym przez Adobe w Photoshopie?
Z bardzo prostego względu. OpenAI przesunęło granicę danych uczących zawierając w nich wizerunki znanych osób prawdopodobnie zawierając dużą część zdjęć ogólnodostępnych i umożliwiło ich wykorzystanie w generowanych obrazach. W Adobe Photoshop nie da się wygenerować podobizny Donalda Trumpa.
A co z prawami autorskimi?
O prawach autorskich wynikających z korzystania z LLM-ów powstanie osobna seria wpisów, bo to temat o którym ciągle dyskutujemy, również z naszym klientami. Na tą chwilę wystarczy że powiem, że temat jest kontrowersyjny.
PS Wszyscy generują swoje podobizny korzystając ze stylu komiksowego studia Ghilbli. Czy jest to naruszeniem praw autorskich?

Więcej w tym temacie niech opowie Wam Kuba Klawiter.
Więcej o nowym modelu dowiecie się tutaj: https://openai.com/index/introducing-4o-image-generation